背景介绍
线上应用经常收到跨服务间SocketTimeout的异常,服务间的调用设置超时时间为500ms,查看Cat监控发现,发生超时异常都伴随着FGC,并且FGC时间都大于500ms,于是决定dump heap镜像。
问题定位分析
通过mat查看heap dump镜像,发现Finalizer引用队列在活跃对象占比高达31.43%,猜测可能有泄漏。
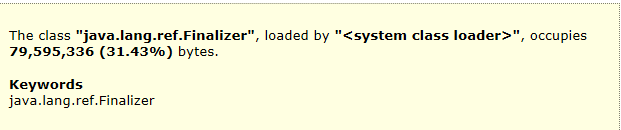
进一步分析发现,SocksSocketImpl对象高达113529多个,大量的对象都是Jedis链接,由此确定Jedis可能发生泄漏,同时查看Old区空间稳步斜率增长,怀疑对象未充分YGC即进入Old区,造成下次FGC较长的STW,引发超时。
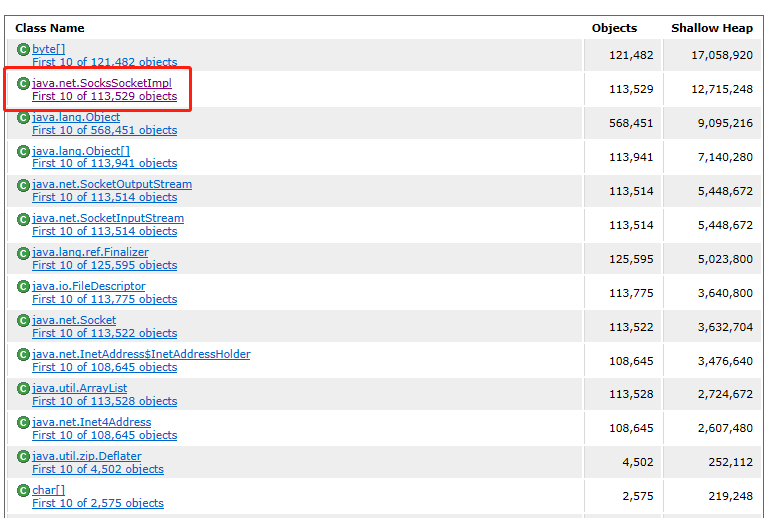
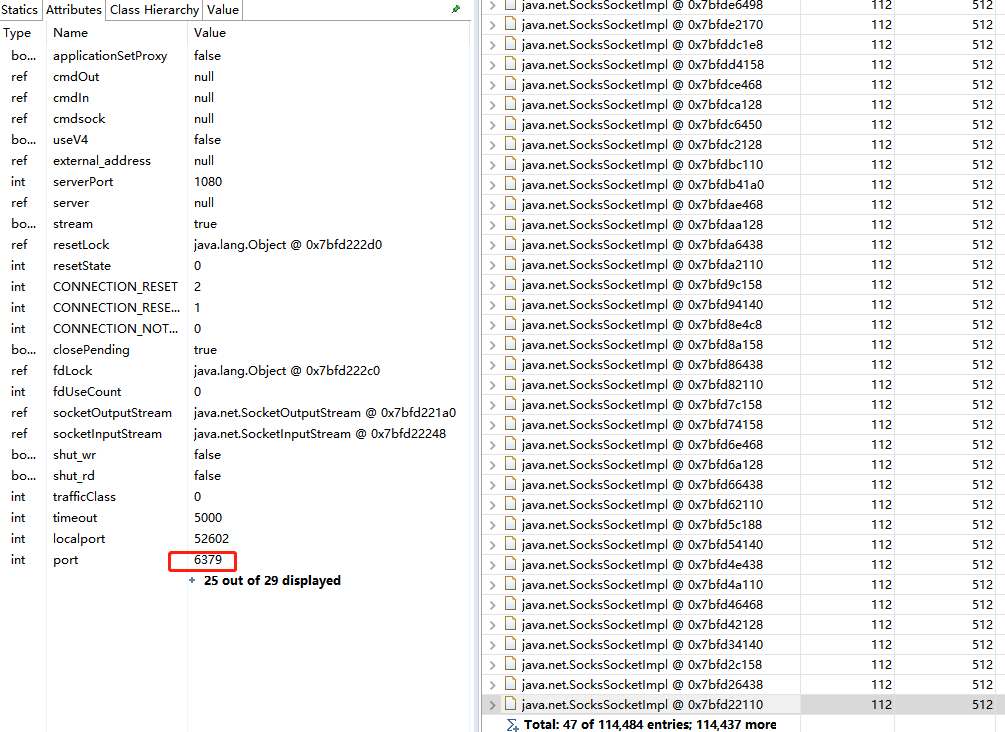
GC问题验证
接下来就是验证上述猜测了,通过获取gc相关的参数,查看JVM各区的容量,发现S0和S1容量被调整非常小大约2m左右,结合收集器配置,情况如下:
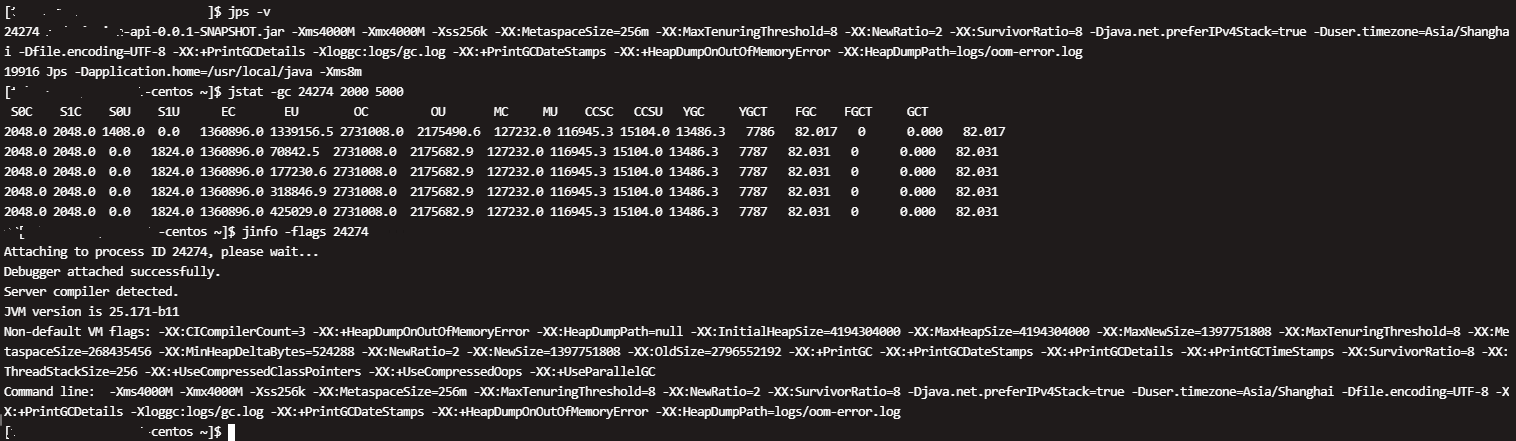
应用采用默认的PS和PO收集器,并且默认开启-XX:+UseAdaptiveSizePolicy,系统会通过吞吐量(cpu的gc时间)计算,优先保证吞吐量来分配Eden,From,To的size,最终导致S0,S1区降为2m。结合GC日志和Cat监控,导致Old的问题就明朗了,每次YGC结束,由于PS和PO收集器的缘故,S0和S1区太小无法,导致配置的晋升参数8几乎失效,对象晋升过快被拷贝到Old区,于是添加-XX:+PrintTenuringDistribution上线验证,得到如下大量GC日志:
Desired survivor size 5048576 bytes, new threshold 1 (max 8)
GC问题调整
上述日志验证猜想,对象由于S0和S1的size太小,晋升过快,问题得到验证,解决就简单了:
- 更换收集器,
PN+CMS或者G1均可 - 仍然采用
PS+PO收集器,关闭-XX:-UseAdaptiveSizePolicy,手动设置Xmn和SurvivorRatio的值
考虑heap内存比较小,4g左右,根据R大的一些分享,采用方案2,进行解决,通过Cat获取S0,S1,Eden的大小以及After FGC后活跃对象的占比,设置对应参数即可,以下来自于美团的设置分享:

根据项目实际监控情况,我们未完全上述经验值,对项目进行更合适的设置如下:
1 | -Xms4G -Xmx4G -Xmn2560M -XX:MetaspaceSize=256M |
Jedis问题解决
上述Jedis垃圾一方面由于GC配置参数不合理导致晋升不合理,查看Jedis的连接池的配置,也进行了调整,查看GenericObjectPool代码,定时任务检测驱逐对象,关键代码如下:
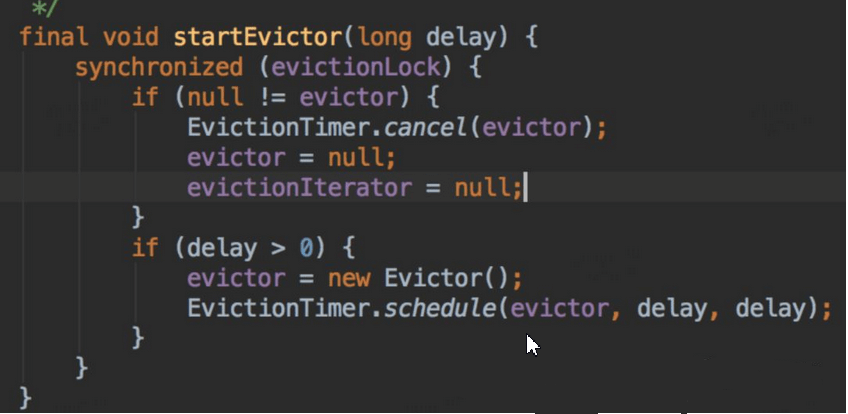
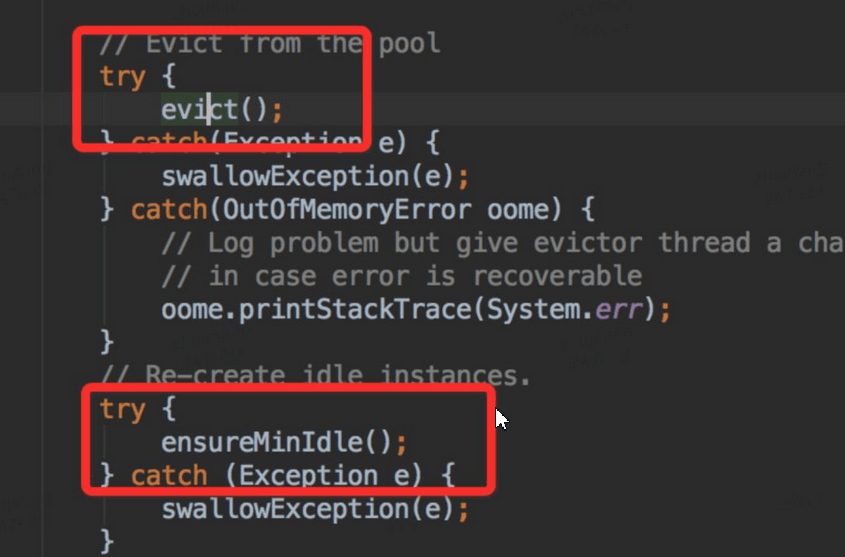
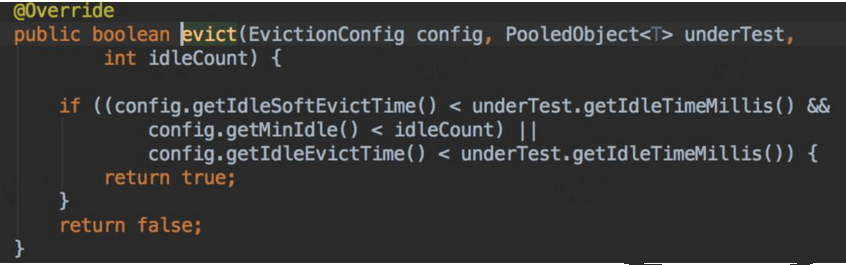
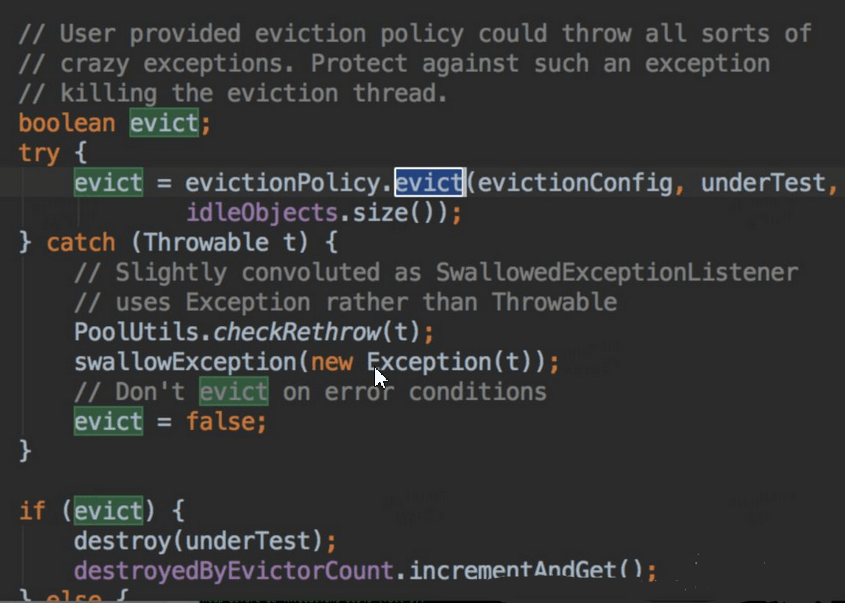
从上面代码我们看出,每隔一段时间,就会检测对象池里面对象,要是发现对象空闲时间超过一定时间,就会强制回收;然后又发现链接少于minIdle了,开始创建对象,以满足mindle。调整Redis client 设置的检测轮询时间为1分钟,设置miniIdle为5,修改后上线观察。
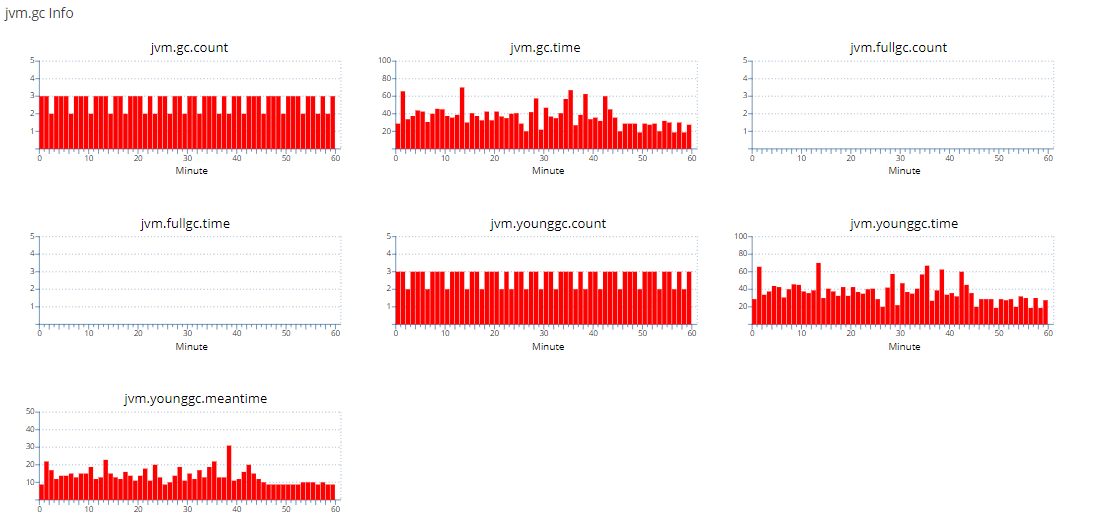
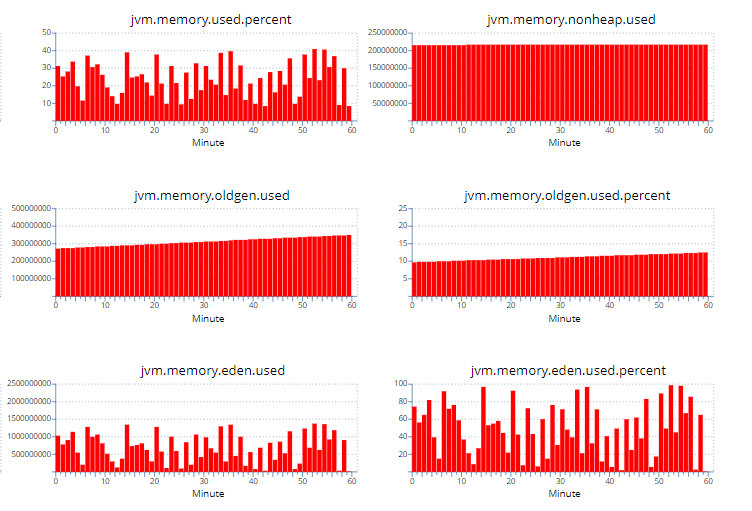
调整前后对比:
调整前:
调整后:
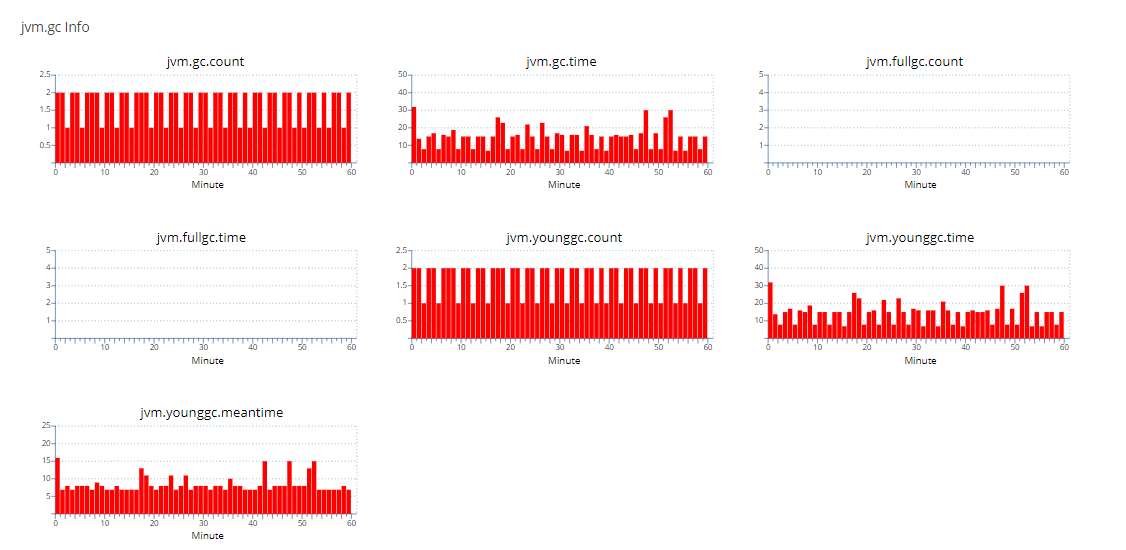
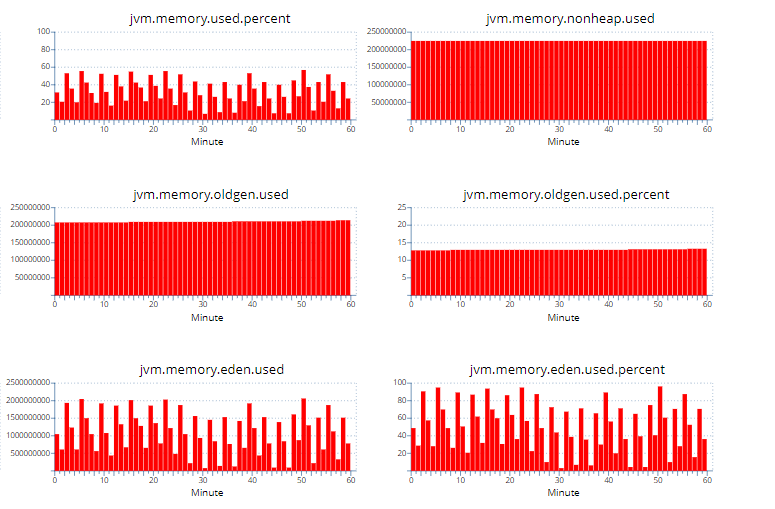
通过上述对比可以看到调整后YGC的次数比调整前减半,调整后的Oldgen也几乎稳定不增长了,YGC由于少了大量的From区往Old区的拷贝(减少Survivor拷贝,GC标记较快,主要耗时为拷贝),YGC时间耗时大幅下降,GC吞吐量获得提升。